Delegating to an LLM Like It's a Junior Engineer
The Question
I wanted to know if I could delegate work to an LLM the way I’d delegate to a person. Not “ask it a question and get a response” delegation—actual structural delegation. Write a ticket, assign it, walk away, get a pull request back. The kind of handoff where you define the work, set the constraints, and trust the process to produce a result.
Most LLM tooling right now is interactive. You sit in a chat window, prompt, review, prompt again. That’s useful, but it’s not delegation. Delegation means the work happens without you in the loop. It means there’s a system—a pipeline with stages, handoffs, quality gates—that takes a unit of work from “filed” to “done” while you do something else.
So I built a prototype to test that idea. It watches a GitHub repo, picks up issues, writes the code, runs the tests, opens a PR, and tells me about it in Slack. It’s been running for a few months. This post is about what the delegation structure looks like and the 218 pull requests’ worth of lessons getting there.
Architecture
The system is called llm-workers. The core idea is that delegation needs structure. You don’t hand a junior engineer a vague Slack message and expect a clean PR back. You give them a well-scoped ticket, a defined workflow, review checkpoints, and guardrails on what they can and can’t touch. The same applies to LLMs.
It’s a Python service that polls GitHub for issues and processes them through a pipeline. I organize work into “departments”—engineering, devops, and qa—where each department is a YAML file defining what stages to run and what the LLM is allowed to do at each stage.
A DepartmentRunner class manages a single department’s lifecycle. A MultiDepartmentRunner wraps them all and runs the departments in threads, sharing a single SQLite database in WAL mode for task coordination. The main loop on each tick does: health check → supervisor poll → advance completed tasks → budget check → schedule pending → swarm execute → SLA breach check → stale task check → heartbeat. The default poll interval is 30 seconds.
The CentralSupervisor handles GitHub issue polling and routes incoming issues to the right department. The SwarmExecutor runs the actual LLM calls. The Scheduler manages priority ordering and backoff. There’s a HealthChecker, an AutonomyManager in the governance module, and a cost_tracker that enforces daily spend limits.
The Pipeline
When a new issue comes in—say, “Add POLL_INTERVAL_SECONDS constant to department_runner.py”—the central supervisor routes it to the engineering department, the system kicks off a Slack thread, and starts working.
Triage is a gate. It reads the issue and decides if it’s well-defined enough to attempt. Too vague? Too large? It gets flagged for human review. Since I write most of these issues knowing they’ll be automated, triage usually passes in a single turn. Triage runs with no tools—just the issue text and the system prompt. This was a deliberate choice after early versions where the triage agent would wander off reading code instead of making a quick routing decision.
Implement does the actual coding. The system provisions a git worktree for isolation—each task gets its own working copy so concurrent tasks don’t step on each other. The worktree.py module manages this. For that POLL_INTERVAL issue, it checked out a feature branch, found the hardcoded polling interval in department_runner.py, pulled it out to a module-level constant, and updated the references. Nothing exotic. The kind of change you’d approve in a PR review without thinking twice.
Test runs the suite and writes new tests if needed. When tests fail, it can loop back to implement, fix what broke, and try again.
Review reads the diff and looks for problems. If it finds something, it bounces the task back to implement.
After review passes, the system creates a PR, links it to the issue, and posts a completion summary to the same Slack thread.
Then the QA department picks it up independently—a separate pipeline with its own stages: analyze → write_tests → validate → report. QA writes its own tests without seeing engineering’s work, validates against its own criteria, and produces its own report. The QA updates post to the same Slack thread as engineering (that took a fix—early versions had QA creating separate threads).
What the Slack Thread Looks Like
For that POLL_INTERVAL issue, the bot posted a “Task Started” message and then logged each stage as it completed.
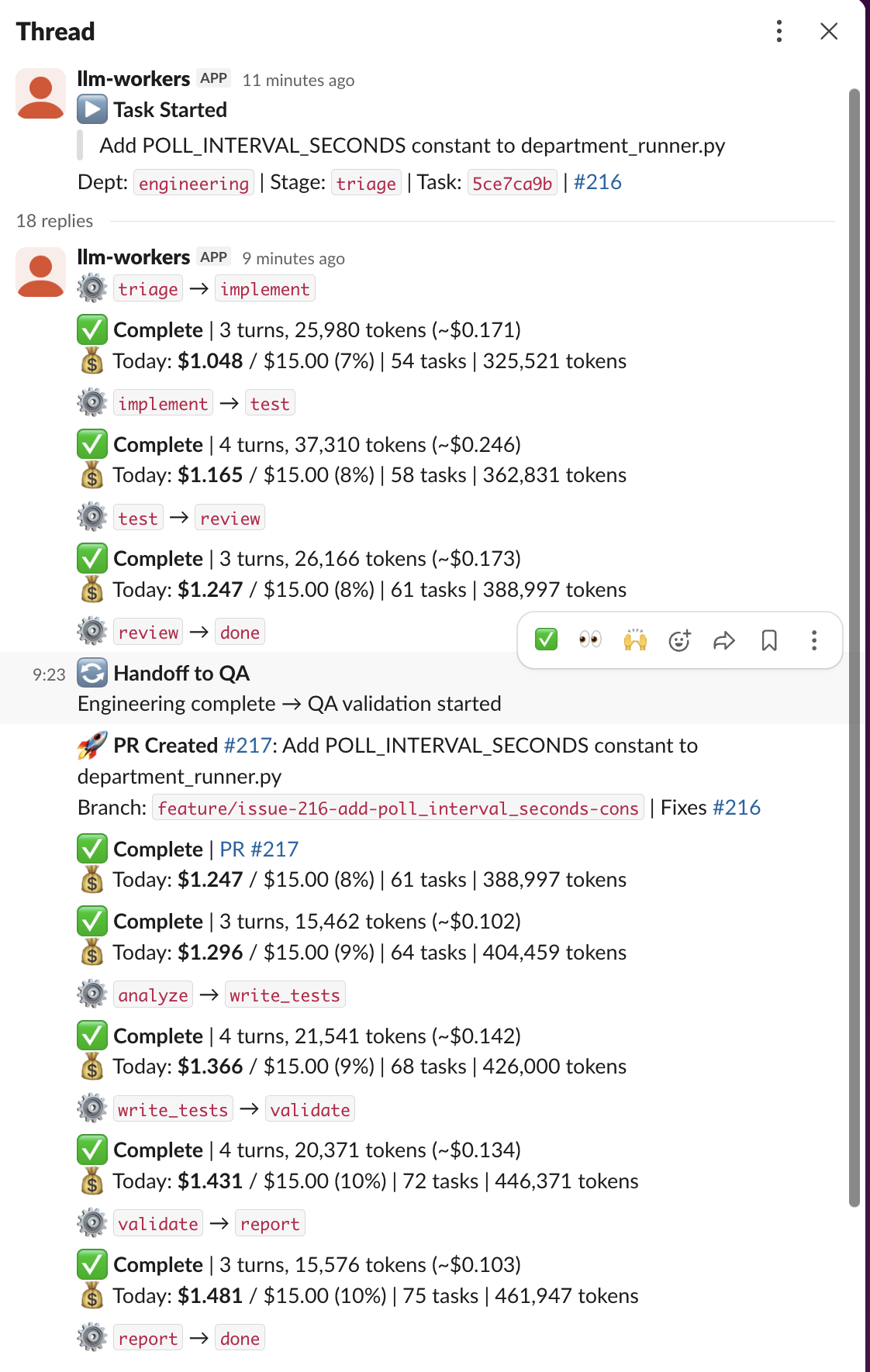
The full engineering run:
- triage → implement: 3 turns, 25,980 tokens (~$0.17)
- implement → test: 4 turns, 37,310 tokens (~$0.25)
- test → review: 3 turns, 26,166 tokens (~$0.17)
- review → done: Complete
Total engineering cost: roughly $0.59 in API calls. Then QA:
- analyze → write_tests: 3 turns (~$0.10)
- write_tests → validate: 4 turns (~$0.13)
- validate → report: 4 turns (~$0.13)
- report → done: Complete
PR created, linked to the issue, branch pushed. Total cost for the entire issue, from triage through QA: about $1.48. The elapsed time was around eleven minutes. The notifier also posts hourly cost summaries to the Slack channel so I can see aggregate burn rate.
The Parts That Were Hard to Get Right
The PR history tells the real story better than any architecture diagram. Here’s roughly what happened, in order.
The model wouldn’t stop
The first version of the agentic loop (agentic_loop.py) had a problem: the model would keep going. It would finish the task, then start improving things, then refactor nearby code, then add documentation it wasn’t asked for. The first fix added an explicit STOP instruction to the system prompt and reduced the maximum turns per stage. A follow-up went further—when the model exhausted its turn limit, the system now treats the result as success if meaningful work was actually done, rather than marking it failed and retrying from scratch.
The model described changes instead of making them
This one took a while to figure out. The implement stage would complete, the model would say “I’ve updated the file to extract the constant,” and the diff would be empty. The model was narrating what it would do instead of calling the Edit tool. The fix was making the implement agent’s system prompt explicitly require tool use—“you MUST use the Edit tool to make changes, do not describe changes.”
Git didn’t work
The system runs in git worktrees, and git operations kept failing in surprising ways. Git commits failed because the worktree didn’t have user.name and user.email configured. The cost tracker’s SQLite database used a relative path that broke inside worktrees—it was writing to a different DB file for every task. Commit info from the implement stage wasn’t persisting through to the review stage, so the system couldn’t create a PR because it didn’t know what branch it was on. Each of these was its own PR to fix. Worktrees are great for isolation but they surface every implicit assumption your code makes about the working directory.
Token burn was out of control
Early versions were burning through API credits fast. The initial approach gave every stage a generous token budget. One round of tightening cut token burn by roughly 70%—fewer tools per stage, shorter system prompts, lower max turns. Then I overcorrected: token budgets were set too low for stages that needed tool use, because tool call/response messages are larger than plain text. Finding the right balance took several iterations.
Cost controls
The token burn problem led to actual cost controls. I added a daily cost cap—$2/day by default—with a Slack alert when it’s hit. That turned out to be too conservative for days with multiple issues queued, so it got bumped to $5/day. Eventually I moved to a rolling budget with an accumulation cap, so unused budget from quiet days carries forward. The cost_tracker.py module in observability/ tracks per-stage costs and the notifier includes cost data in every Slack update.
Model selection
Not every stage needs the same model. I split model selection: Haiku 4.5 for cheap roles (triage, review) and Sonnet for implementation, later upgraded to Sonnet 4.6. The agent_registry.py in src/registry/ manages these configurations—which model, which tools, which system prompt for each stage in each department. Triage on Haiku costs almost nothing. Review on Haiku is fast and cheap and catches the obvious stuff. Implementation needs the bigger model because it’s actually writing code.
Deployment
The system started as a Docker container, which added complexity without much benefit for a single-process Python service. I replaced Docker with a plain virtualenv and a systemd unit on a cheap Linux box. Then the deploy workflow itself took about ten PRs to get right—SSH keyscan issues, sudoers syntax errors, git authentication on first deploy.
The Guardrails
The guardrails.py module enforces tool access per stage at the execution layer. Implement can write code but can’t touch CI config. Test can run commands but can’t push to remote. Review can read the diff but can’t merge. Putting these constraints in the system prompt didn’t work—the model would occasionally ignore them. Moving guardrails from prompt instructions to code enforcement was one of the biggest reliability improvements. When a stage tries to call a tool it doesn’t have, the call gets rejected before anything happens.
The governance/autonomy.py module handles a separate concern: how much autonomy the system has at any given time. The department runner’s main loop includes an “autonomy promotion check” step—the system can escalate or restrict its own permissions based on success rates and error patterns.
What I Took From Claude Code
A lot of the design decisions in llm-workers came from using Claude Code daily and watching where it succeeds and where it falls apart. I wrote about Claude Code’s memory system earlier—the indeterminism, the budget limits, the compaction problem. Building llm-workers was partly an exercise in applying those lessons to a system I control end-to-end.
Stage separation is sub-agents by another name. Claude Code spawns sub-agents via the Task tool, and each one gets a completely fresh context with no conversation history from the parent. That’s exactly what the pipeline stages do. Triage doesn’t carry context into implement. Implement doesn’t carry context into test. Each stage starts clean with only the information it needs. This avoids the context rot problem that plagues long Claude Code sessions—where the model gradually forgets earlier instructions as compaction summarizes them away. By keeping each stage short and focused, there’s nothing to compact.
Tool restrictions work better in code than in prompts. Claude Code has a permission system that gates tool access, but it’s designed for interactive use—the user approves or denies. In an autonomous system, you can’t have permission dialogs. The guardrails module came from watching Claude Code occasionally ignore system prompt instructions about what tools to use. The --dangerously-skip-permissions flag that autonomous Claude Code setups require is an honest admission that prompt-level tool control isn’t reliable enough for unattended operation. So I built the restriction layer outside the model.
The Ralph Wiggum loop is the test stage. The iterate-until-done pattern that Geoffrey Huntley popularized and Anthropic turned into a plugin—that’s exactly what happens when the test stage fails and loops back to implement. Don’t expect the first attempt to be correct. Expect the loop to converge. The difference is that in llm-workers the retry is scoped to a specific stage transition, not the whole task. A failed test doesn’t restart triage. It just re-enters implement with the failure context.
CLAUDE.md rules are department YAML files. Claude Code’s memory system loads persistent instructions from CLAUDE.md files at various directory levels. The department YAML configs serve the same purpose: persistent, structured instructions that define behavior per context. But where CLAUDE.md competes for attention in a shared context window and can get truncated or compacted away, the department configs are loaded fresh for each stage and enforced programmatically. The lesson from the memory system’s 40,000-character budget was: don’t put everything in one place and hope the model attends to all of it. Separate concerns into separate stages with separate instructions.
Worktrees came straight from my Claude Code workflow. I use git worktrees for all branch work in Claude Code—it’s in my CLAUDE.md rules. The same pattern maps directly to concurrent task execution: each task gets its own worktree, its own branch, its own isolated working copy. The bugs I hit (relative paths breaking, git config missing, state not persisting across stages) were all things I’d already encountered using worktrees in Claude Code, just surfaced again in an automated context where there’s no human to notice and fix them.
What I’ve Learned
The delegation boundary is sharper than I expected. The system handles “extract this constant” and “add this return type” reliably. It struggles with anything requiring design judgment. The dividing line maps pretty closely to what you’d hand a contractor who doesn’t have context on your product: if the issue can be fully specified in the ticket, it works. If it requires understanding why the code is structured a certain way, it doesn’t. I’ve started writing issues in a style that works for delegation—clear acceptance criteria, specific file references, bounded scope. The audience is a machine, and writing for that audience is its own skill.
The multi-stage pipeline is the thing that made delegation actually work. Early versions tried to do everything in one shot—a single LLM call that would triage, implement, test, and review. That’s not delegation, that’s hoping. Splitting into stages with separate contexts, separate tool sets, and explicit handoffs between them is what turned it from a demo into something I trust. Giving triage zero tools was a key insight. Requiring the implementer to use Edit explicitly instead of narrating changes was another. Each stage does one job, and the structure enforces that.
The “department” metaphor isn’t just naming. It captures something real about how delegation works at scale. Engineering and QA having separate pipelines with separate quality criteria means I get independent verification without coordinating it myself. The central supervisor routing issues to the right department means I don’t have to think about which pipeline handles what. The whole point of organizational structure is that the structure makes decisions so individuals don’t have to. That applies whether the individuals are people or models.
Running departments in threads with a shared SQLite DB turned out to be simpler than I expected. WAL mode handles the concurrency. The whole thing is one Python process on one box. I expected to need message queues or at least Redis. I didn’t.
How This Differs From Copilot’s Coding Agent
GitHub’s Copilot coding agent does something similar on the surface. You assign Copilot to a GitHub issue, it spins up a GitHub Actions environment, writes code, opens a PR, and asks you to review. If you leave comments, it revises. It’s a polished product and it works.
But it’s a black box. You get one pipeline, one model, one set of behaviors. You can add a prompt when you assign the issue, but you can’t change how the agent decomposes work, what stages it goes through, which model runs at each stage, or what tools are available at each step. There’s no concept of departments, no independent QA pipeline, no cost caps you control, no way to enforce that triage can’t read code or that review must run at a lower temperature. The agent decides how to approach the task, and you find out what it did when you read the PR.
The thing I built is worse in almost every surface-level way. It’s uglier, harder to set up, and took 218 PRs to get to “mostly works.” But I can look at the engineering YAML and know exactly what stages a task will go through. I can put Haiku on triage because it doesn’t need Sonnet’s reasoning for a yes/no gate. I can enforce in code that the implement stage can’t push to remote, not just hope the model listens. I can run QA as a completely separate department with its own test suite and its own verdict. I can set a daily cost cap and a rolling budget. I can see every stage’s token count in the Slack thread.
The difference is control over the delegation structure itself. Copilot gives you a managed delegate. This gives you the management layer. For a single developer’s side project, Copilot is probably the right call. But if you want to understand how structured delegation to LLMs actually works—what breaks, what the failure modes are, where the model needs constraints versus autonomy—you have to build the structure yourself. The structure is the interesting part.
What This Is Really About
This isn’t a productivity hack. It’s a prototype of a delegation model. The question I started with—can I hand off structured work to an LLM the way I’d hand it to a person—has a qualified yes as the answer. The qualification is that the structure has to do most of the work. The LLM is the engine, but the pipeline, the guardrails, the stage separation, the department routing, the cost controls—that’s what makes the engine useful. Without that structure, you just have a chatbot with git access.
The interesting part isn’t that an LLM can write code. It’s that you can build a system around an LLM that decomposes work, enforces constraints, verifies results, and reports status—the same things you’d build around any team of workers. The department YAML files are basically job descriptions. The guardrails are access controls. The Slack threads are standup updates. It’s project management infrastructure that happens to manage models instead of people.
What’s Next
The delegation model is still one-directional: I file an issue, the system processes it, I merge or close the PR. The missing piece is a feedback loop. Right now, if a PR needs changes, my only options are to make the edit myself or close it and file a better-scoped issue. I want to be able to leave a comment on the PR and have the system pick it back up at the implement stage with my feedback as context. That’s how delegation works with people—you review, give notes, they revise. The system should support the same loop.
The other extension is issue generation. The system could scan for TODO comments, missing type annotations, deprecated API usage, and file issues for itself to process. That moves the delegation from reactive to proactive—the system finds its own work instead of waiting for me to define it. Whether that’s a good idea is a separate question. Autonomous work discovery is where the delegation metaphor starts to stretch.
References
- Anthropic Claude API — Sonnet 4.6 for implementation, Haiku 4.5 for triage and review
- Claude Code Hooks Documentation — Event-driven hooks for autonomous agent loops
- Geoffrey Huntley’s Ralph Wiggum Technique — The iterate-until-done philosophy behind the retry logic